이번 글에서는 python의 sklearn 모듈의 pipeline에 대한 예제를 다뤄볼 예정이다.
앞의 글
[데이터 분석] Data Leakage Part 2. Pipeline architecture
[데이터 분석] Data Leakage Part 3. sklearn.pipeline
을 참고하면 이해하는데 도움이 될 수 있다.
1. Pipeline 사용법
간단하게 ①변수선택 → ②표준화 → ③모형학습 3단계를 가정해 보자.
1) Pipeline을 사용하지 않았을 경우
기존 방식대로 위의 3단계를 수행할 경우 ①변수선택부터 ②표준화, ③모형학습까지 각각 하나하나 코딩해야 한다.
# 필요한 라이브러리 불러오기
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
## 붓꽃 데이터 준비
iris = load_iris() # 붓꽃 데이터 불러오기
X = iris.data # 데이터에서 특징 변수를 X에 할당
y = iris.target # 데이터에서 목적 변수를 y에 할당
## 변수 선택
feat_sel = SelectKBest(f_classif, k=2) # f_classif 방법으로 k=2개 변수 선택
X_selected = feat_sel.fit_transform(X, y) # 선택된 변수를 X_selected에 할당
print('선택된 변수 :', feat_sel.get_feature_names_out()) # 선택된 변수 이름 출력
print()
## 표준화
scaler = StandardScaler() # StandardScaler() 객체 생성
scaler.fit(X_selected) # X_selected 데이터에 맞게 표준화를 적합
X_transformed = scaler.transform(X_selected) # 표준화된 데이터를 X_transformed에 할당
print(X_transformed[:5, :]) # 처음 5개 샘플의 표준화된 데이터 출력
print()
## 모델 학습
clf = DecisionTreeClassifier(max_depth=3) # 최대 깊이가 3인 의사결정나무 모델 생성
clf.fit(X_transformed, y) # 모델 적합
print('예측 : ', clf.predict(X_transformed)[:3]) # 처음 3개 샘플에 대한 예측 결과 출력
print('학습 정확도 : ', clf.score(X_transformed, y)) # 모델의 학습 정확도 출력
2) Pipeline을 이용한 간단한 과정
앞의 코드를 pipeline을 사용하여 나타내 보자.
pipeline에는 (작업명, 작업클래스)로 이루어진 튜플을 리스트로 담아야 한다.
Pipeline ( [ '작업명 1', 작업클래스 1 ), ( '작업명 2', 작업클래스 2),... ] )
Pipeline에 작업을 등록해 주고 fit을 통해 학습만 해주면 된다.
## 작업 등록
pipeline = Pipeline([('Feature_Selection', SelectKBest(f_classif, k=2)), # 변수 선택
('Standardization', StandardScaler()), # 표준화
('Decision_Tree', DecisionTreeClassifier(max_depth=3)) # 학습 모델
])
pipeline.fit(X, y) # 모형 학습
print(pipeline.predict(X)[:3]) # 예측
print(pipeline.score(X, y)) # 성능 평가
2-1) make_pipeline을 이용한 Pipeline 작업 자동생성
make_pipeline을 이용하면 작업 클래스만 입력하여 자동으로 작업명이 생성되기 때문에 좀 더 편하다.
pipeline = make_pipeline(SelectKBest(f_classif, k=2),
StandardScaler(),
DecisionTreeClassifier(max_depth=3))
pipeline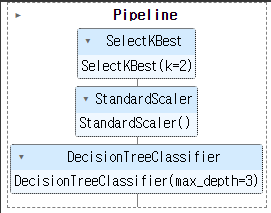
3) Pipeline의 중간 결과 확인하기.
Pipeline을 이용하면 모델 학습과 최종 예측 결과만 확인된다.
간혹 선택된 변수, 표준화 작업내용 등을 확인하고 싶다면 두 가지 방법으로 중간 결과 확인이 가능하다.
3-1) 인덱스를 이용한 중간 결과 확인 방법
## 중간 결과 보기 - 인덱스를 이용한 방법
## 선택된 변수 보기
var_selected = pipeline[0].fit_transform(X, y) # 파이프라인의 첫 번째 단계인 FeatureSelection을 적용한 후 선택된 변수들만 추출
print('선택된 변수 :', pipeline[0].get_feature_names_out()) # FeatureSelection으로 선택된 변수들의 이름 출력
print()
## 표준화가 잘되었는지 확인하기
var_selected = pipeline[0].get_feature_names_out()
X_selected = X[:,[int(x.replace('x','')) for x in var_selected]] # 선택된 변수들의 인덱스를 이용해 X에서 해당 변수들만 추출
X_transformed = pipeline[1].fit_transform(X_selected) # 파이프라인의 두 번째 단계인 StandardScaler를 이용해 데이터 표준화
print(X_transformed[:5, :]) # 표준화된 데이터의 처음 5개 행 출력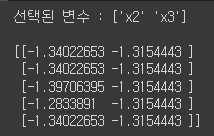
3-2) named_steps을 이용한 중간 결과 확인 방법
Pipeline에서는 named_steps를 이용하여 각 작업 과정을 딕셔너리로 접근할 수 있다.
pipeline.named_steps
위의 딕셔너리를 사용하여 중간 결과를 확인해 보자.
## 중간 결과 보기 - named_steps 이용한 방법
## 선택된 변수 보기
var_selected = pipeline.named_steps['selectkbest'].fit_transform(X, y) # 파이프라인의 selectkbest 단계를 적용한 후 선택된 변수들만 추출
print('선택된 변수 :', pipeline.named_steps['selectkbest'].get_feature_names_out()) # selectkbest 단계에서 선택된 변수들의 이름 출력
print()
## 표준화가 잘되었는지 확인하기
var_selected = pipeline.named_steps['selectkbest'].get_feature_names_out() # selectkbest 단계에서 선택된 변수들의 이름 추출
X_selected = X[:,[int(x.replace('x','')) for x in var_selected]] # 선택된 변수들의 인덱스를 이용해 X에서 해당 변수들만 추출
X_transformed = pipeline.named_steps['standardscaler'].transform(X_selected) # 파이프라인의 StandardScaler 단계를 이용해 데이터 표준화
print(X_transformed[:5, :]) # 표준화된 데이터의 처음 5개 행 출력
두 가지 방법으로 중간 결과도 확인이 가능하다.
2. 글 마무리
이로써 Pipeline을 이용한 간단한 예제를 실습해 보았다.
아직 미흡하여 여러 번 실습해 보며 익힐 필요가 있어 보인다.
다음에는 좀 더 나아가 시각화도 이용해 보도록 하겠다.
'머신러닝' 카테고리의 다른 글
| [데이터 분석] Data Leakage Part 3. sklearn.pipeline (0) | 2023.04.21 |
|---|---|
| [데이터 분석] Data Leakage Part 2. Pipeline architecture (1) | 2023.04.21 |
| [데이터 분석] Data Leakage Part 1. (0) | 2023.04.20 |
| [데이터 분석] Feature Engineering (0) | 2023.04.19 |